细胞注释
用途
使用cell2location做解卷积细胞注释
运行方式
SDAS cellAnnotation cell2location -i st.h5ad -o outdir --reference_csv ./ref/inf_aver.csv \
--bin_size 20 \
--input_gene_symbol_key _index \
--gpu_id 3
输入参数说明
| 参数 | 是否必须 | 默认值 | 描述 |
|---|---|---|---|
| -i / --input | 是 | Stereo-seq h5ad,要求有原始表达矩阵 | |
| -o / --output | 是 | 输出文件夹 | |
| --reference_csv | 是 | 单细胞ref csv文件 | |
| --bin_size | 是 | Bin大小,用于控制每个bin的细胞数和图中点的大小; 如20, 50, 100, cellbin (等效于20) | |
| --input_layer | 否 | Stereo-seq h5ad存放raw counts的layer | |
| --input_gene_symbol_key | 否 | real_gene_name | Stereo-seq h5ad.var中表示基因名(symbol)的列的名称 (_index 表示使用h5ad.var.index) |
| --slice_key | 否 | sampleID | 多片h5ad.obs中表示片编号的列的名称,提供批次信息和用于画图 |
| --detection_alpha | 否 | 20 | 规则化参数。空转数据的技术性变异越大,适合的detection_alpha越小,一般不调整 |
| --data_split_strategy | 否 | chunk | 当bin数量太大时,对空转数据进行拆分,此参数为数据拆分策略。chunk表示先随机拆分再运行cell2location,batch表示在算法内部进行拆分 |
| --data_split_size | 否 | 10000 | 当bin数量太大时,对空转数据进行拆分,此参数为拆分的数据大小。越大运行得越快,但所占显存也越大。如果为-1,则不进行拆分 |
| --max_epochs | 否 | 5000 | 模型训练epoch数 |
| --seed | 否 | 42 | 随机种子设置 |
| --gpu_id | 否 | -1 | 使用的GPU的编号,如果为-1,则使用CPU。 此参数只指定主要使用的GPU,其他GPU也会被占用,但占用量很低。如果需要严格指定GPU,请在运行前设置环境变量,如: export CUDA_VISIBLE_DEVICES=2,此时再设置--gpu_id 0,则会只使用2号GPU |
| --n_threads | 否 | CPU模式下使用的线程数,默认为全部CPU |
输出结果展示
| 结果文件 | 描述 |
|---|---|
<input_name>_anno_cell2location.csv |
每个spot的注释结果,包括每种细胞类型的分数(分数来源于cell2location计算的q05_cell_abundance_w_sf) |
<input_name>_anno_cell2location.h5ad |
输入h5ad+注释结果。每个细胞类型的分数存在obsm['anno_score_cell2location']中,分数最高的类型存在obs['anno_cell2location']中 |
<input_name>_anno_cell2location.png/pdf |
总体注释结果图,多片情况下每片画一张图,同时输出png和pdf |
<input_name>_anno_cell2location_split.png/pdf |
每个细胞类型分开展示图,多片情况下每片画一张图,同时输出png和pdf |
<input_name>_anno_score_cell2location.png/pdf |
每个细胞类型的分数图,多片情况下每片画一张图,同时输出png和pdf |
- 总体注释结果图:
<input_name>_anno_cell2location.png/pdf颜色代表每个bin/cellbin的占比最高的细胞类型

- 细胞类型分开展示结果图:
<input_name>_anno_cell2location_split.png/pdf颜色代表每个bin/cellbin的占比最高的细胞类型,标题为细胞类型(细胞个数)
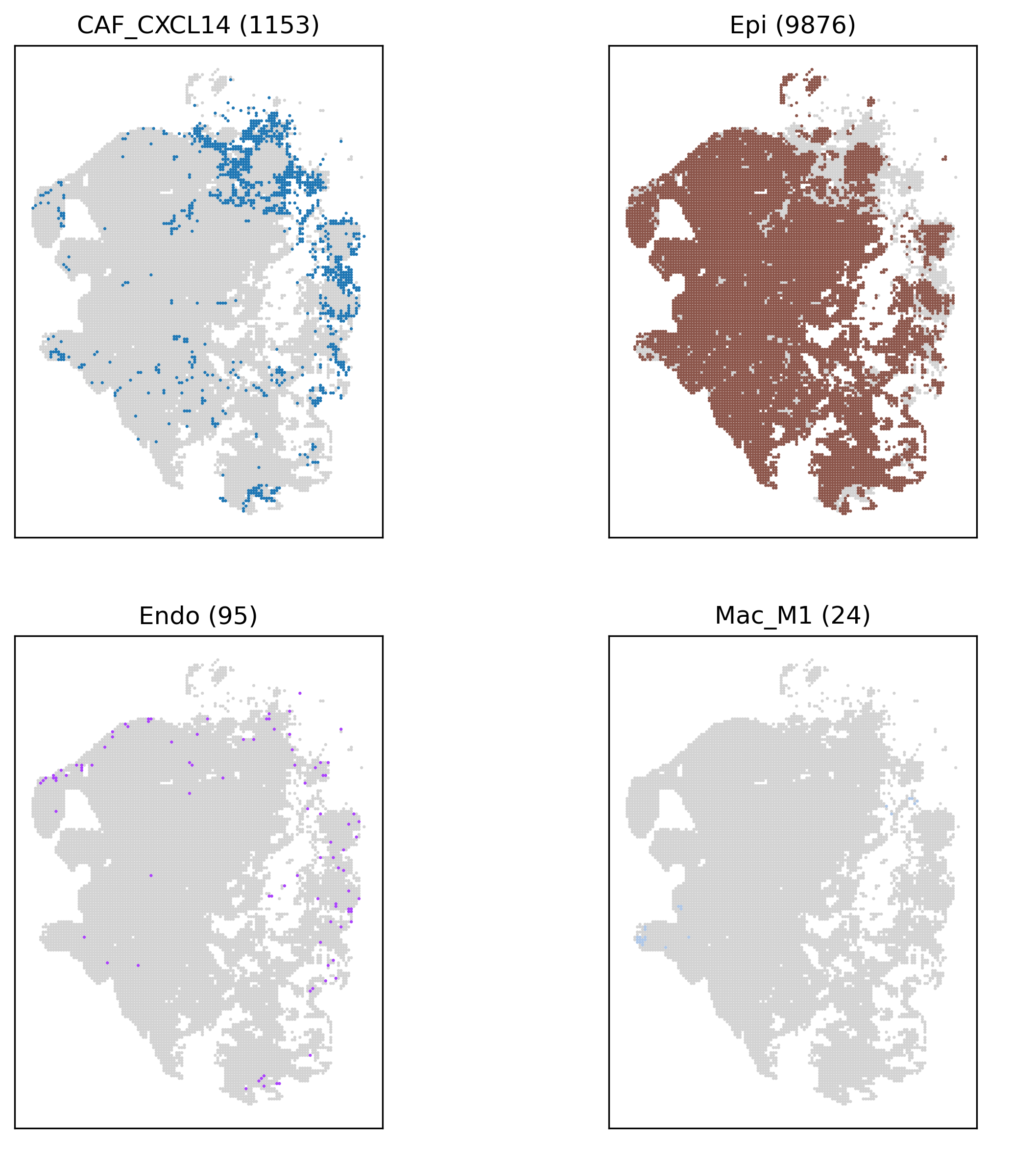
- 细胞类型分数图:
<input_name>_anno_score_cell2location.png/pdf算法计算的不同细胞类型的分数。分数越高,该细胞类型占比越高
- 注释结果csv:
<input_name>_anno_cell2location.csv每一行为一个bin/cellbin,每一列为一个细胞类型,数值为细胞类型分数,分数越高,该细胞类型占比越高。最后一列 (annotation) 为此bin/cellbin中占比最高的细胞类型
| index | B_act | B_naive | CD4_CXCL13 | ... | annotation |
|---|---|---|---|---|---|
| CRCP95_T_BIN.242 | 0.1689 | 0.1694 | 0.2176 | ... | CAF_CXCL14 |
| CRCP95_T_BIN.243 | 0.1122 | 0.2350 | 0.1745 | ... | Epi |
| CRCP95_T_BIN.244 | 0.1020 | 0.2062 | 0.1527 | ... | Epi |
| CRCP95_T_BIN.245 | 0.0808 | 0.1980 | 0.1668 | ... | Epi |
| ... | ... | ... | ... | ... | ... |